


Machine learning projects can transform entire organizations, but the success of deployment often depends on one overlooked detail. Over 60 percent of failed enterprise ML deployments are traced back to poor infrastructure assessment and weak environment configuration. Most teams focus on algorithms, but the truth is even the best models flop if your systems and setup are not deployment-ready. Unpacking the real keys to reliable ML project rollout may surprise you.

Successful ml project deployment begins with a comprehensive evaluation of your existing technological ecosystem. Understanding your current infrastructure is crucial for identifying potential bottlenecks, compatibility challenges, and resource gaps that could impede machine learning implementation.
Starting your assessment requires a systematic examination of your computational resources, networking capabilities, and data management infrastructure. You will need to analyze several critical components that directly impact ML project performance. Hardware specifications play a fundamental role in determining your deployment readiness. This includes evaluating processor types, GPU capabilities, memory configurations, and storage infrastructure.
According to NIST Special Publication, a thorough infrastructure review should consider multiple interconnected dimensions:
Your evaluation should involve detailed documentation of existing systems, creating an inventory that maps current technological assets against anticipated ML workload requirements. Pay special attention to computational performance metrics, understanding how your current infrastructure aligns with the computational demands of your specific machine learning models.
Key verification indicators that your infrastructure assessment is comprehensive include generating a detailed report documenting current capabilities, identifying potential upgrade paths, and creating a gap analysis between existing resources and ML project needs. Precise documentation becomes your roadmap for subsequent infrastructure optimization and ml project deployment strategies.
The following table summarizes key verification steps you should complete during your infrastructure assessment, helping ensure readiness for a successful machine learning project deployment.

Remember that infrastructure assessment is not a one-time event but an ongoing process. Technology evolves rapidly, and your ml project deployment strategy must remain flexible and adaptable to emerging computational technologies and changing organizational requirements.
After completing your infrastructure assessment, configuring the deployment environment becomes the critical next phase in ml project implementation. This step transforms your theoretical infrastructure plan into a practical, operational framework capable of supporting complex machine learning workflows.
Environment configuration involves creating a standardized, reproducible setup that ensures consistency across development, testing, and production stages. Your primary goal is establishing a robust technological ecosystem that can seamlessly integrate machine learning models while maintaining performance, security, and scalability.
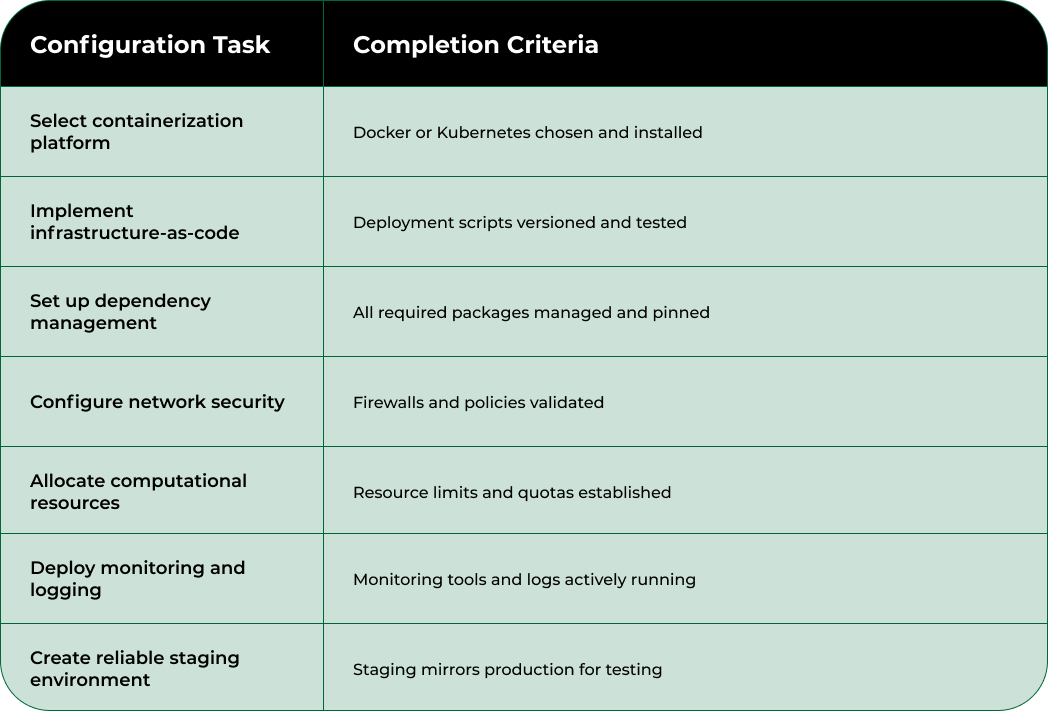
According to arXiv Research, effective environment configuration requires meticulous attention to several interconnected technical dimensions. Begin by selecting appropriate containerization technologies like Docker or Kubernetes, which provide isolated, portable environments for your ml project deployment. These platforms enable you to encapsulate dependencies, ensuring that your machine learning models can run consistently across different computational infrastructures.
Your configuration process should prioritize creating reproducible environments through infrastructure-as-code principles. Utilize configuration management tools such as Ansible, Terraform, or CloudFormation to script and version your entire deployment infrastructure. This approach guarantees that every team member can replicate the exact same environment, reducing potential configuration discrepancies.
Key configuration elements to address include:
Pay special attention to creating a staging environment that closely mirrors your production setup. This allows for comprehensive testing and validation before final deployment. Implement robust logging and monitoring solutions that provide granular insights into system performance, resource utilization, and potential bottlenecks.
Verification of successful environment configuration involves running comprehensive test suites, ensuring all dependencies are correctly installed, and validating that your ml models can be deployed and executed without unexpected errors. Your configuration should support seamless model training, inference, and continuous integration processes.
This checklist table helps you keep track of environment configuration tasks, ensuring your deployment setup is robust, reproducible, and ready for machine learning workflows.
Remember that environment configuration is not a static process but an ongoing optimization journey. Regularly review and refine your setup to accommodate evolving machine learning technologies and organizational requirements.
Integrating and calibrating machine learning models represents a pivotal transition from theoretical development to practical enterprise deployment. This critical phase transforms your carefully crafted algorithms into reliable, performant solutions that can deliver consistent, actionable insights across your organizational ecosystem.
Model integration demands a holistic approach that goes beyond simple algorithm implementation. You will need to create seamless connections between your ml models and existing enterprise systems, ensuring smooth data flow, minimal latency, and robust interoperability. This process involves carefully mapping model outputs to specific business processes and establishing clear communication protocols between different technological components.
According to recent machine learning research, calibrating predictive models is essential for generating trustworthy and reliable predictions. Calibration ensures that your model’s confidence scores accurately represent the actual probability of predictions, which is crucial for decision-making in enterprise environments.
Your integration strategy should focus on creating flexible architectural frameworks that allow for modular model deployment. Implement robust API interfaces that can handle variations in input data, manage computational resources efficiently, and provide clear mechanisms for model versioning and rollback.
Key considerations during integration include:
Performance calibration requires systematic validation across multiple dimensions. This involves running extensive test scenarios that challenge your model’s predictive capabilities under diverse conditions. Develop comprehensive validation frameworks that assess not just raw accuracy, but also model robustness, generalizability, and computational efficiency.
Verification of successful model integration involves demonstrating consistent performance across different datasets, minimal prediction drift, and alignment with established business key performance indicators. Your integrated ml models should provide transparent, interpretable results that enable stakeholders to understand and trust the underlying computational processes.
Remember that model integration is an iterative process. Continuously refine your approach, monitoring model performance and adapting to changing organizational requirements and technological landscapes.
The deployment process represents the critical moment where your meticulously prepared machine learning models transition from development to active production environments. This stage demands precision, strategic planning, and robust automation to ensure smooth, reliable ml project deployment across enterprise infrastructure.
Deployment execution is not a single event but a carefully orchestrated sequence of technical and operational actions. Your primary objective is to minimize disruption while maximizing the reliability and performance of your machine learning solutions. This requires a systematic approach that balances technical implementation with organizational readiness.
According to Google Cloud MLOps Practices, implementing automated deployment pipelines significantly reduces manual intervention and mitigates potential human error during model rollouts. Leverage continuous integration and continuous deployment (CI/CD) frameworks specifically designed for machine learning workflows to streamline your execution strategy.
Begin by establishing a comprehensive deployment runbook that outlines explicit steps, contingency protocols, and rollback mechanisms. This document serves as your tactical guide, ensuring consistent execution across different models and reducing variability in deployment processes. Prioritize incremental deployment strategies that allow for controlled, phased implementation, enabling real-time performance monitoring and rapid intervention if unexpected challenges emerge.
Key deployment execution considerations include:
Your deployment process should incorporate rigorous validation checkpoints that assess model performance, system compatibility, and computational resource utilization.

Develop synthetic test scenarios that simulate production environments, allowing you to identify potential performance bottlenecks or integration challenges before full-scale implementation.
Verification of successful deployment involves demonstrating consistent model performance, minimal system disruption, and alignment with predefined operational metrics. Track key indicators such as prediction latency, resource consumption, and accuracy across different computational loads.

Remember that deployment is an iterative process. Maintain flexibility in your approach, continuously refining your strategies based on real-world performance data and emerging technological capabilities.
Validation and testing represent the critical quality assurance phase of ml project deployment, where your machine learning models undergo comprehensive scrutiny to ensure they meet enterprise performance standards. This step transforms theoretical model potential into measurable, reliable operational capabilities.
Systematic validation requires a multifaceted approach that goes beyond traditional performance metrics. Your testing strategy must simulate real-world scenarios, challenge model assumptions, and provide transparent insights into predictive capabilities across diverse computational environments.
According to research on machine learning model evaluation, post-deployment testing should incorporate continuous monitoring of model drift, unexpected outlier events, and complex edge cases. This proactive approach helps detect potential performance degradation before it significantly impacts business operations.
Begin by developing a comprehensive test suite that covers multiple evaluation dimensions. This involves creating synthetic datasets that represent various operational scenarios, stress-testing your model’s predictive capabilities under different computational loads and input variations. Rigorous testing is not about achieving perfection but understanding model limitations and boundary conditions.
Key validation components to address include:
Implement advanced monitoring frameworks that provide real-time insights into model performance. These systems should generate detailed logs, track prediction confidence intervals, and automatically flag potential anomalies that require human intervention. Develop clear escalation protocols that enable rapid response to any detected performance deviations.
Verification of successful validation involves demonstrating consistent model performance, transparent predictability, and alignment with predefined enterprise requirements. Your testing outcomes should provide clear, quantifiable evidence of the model’s operational readiness and potential business value.
Remember that validation is an ongoing process. Continuously refine your testing methodologies, incorporate feedback loops, and remain adaptable to emerging technological capabilities and changing organizational needs.
Continuous performance monitoring and resource optimization represent the sustained lifecycle management of your machine learning deployment. This critical phase transforms initial deployment into a dynamic, adaptive technological ecosystem that can evolve with changing computational demands and organizational requirements.
Performance monitoring is not a passive observation but an active, strategic intervention. Your approach must integrate comprehensive tracking mechanisms that provide granular insights into model behavior, computational efficiency, and potential optimization opportunities. This requires establishing a robust observability framework that goes beyond traditional metric collection.
Begin by implementing advanced monitoring tools that capture multidimensional performance data. These systems should track not just model prediction accuracy, but also computational resource consumption, latency, throughput, and potential emerging behavioral patterns. Real-time monitoring enables proactive management, allowing you to identify and address potential performance bottlenecks before they significantly impact operational efficiency.
Key monitoring and optimization focus areas include:
Develop dynamic resource allocation strategies that can automatically adjust computational resources based on workload variations. This might involve implementing intelligent scaling mechanisms that can expand or contract computational capacity in response to changing prediction demands, ensuring optimal resource efficiency without compromising performance.
Critical to your monitoring approach is establishing clear performance benchmarks and creating automated alerting systems that can quickly identify deviations from expected operational parameters. These alerts should provide contextualized information that enables rapid diagnostic and corrective actions.
Verification of successful monitoring involves demonstrating consistent model performance, efficient resource utilization, and the ability to quickly adapt to changing computational requirements. Your optimization strategies should result in measurable improvements in computational efficiency, reduced operational costs, and maintained predictive accuracy.
Remember that resource optimization is an ongoing journey. Continuously refine your monitoring approaches, integrate emerging technologies, and remain adaptable to the evolving machine learning technological landscape.
You have spent countless hours assessing infrastructure, configuring environments, and calibrating models. Yet the biggest roadblock always comes back to hardware bottlenecks and unpredictable procurement when it is time to scale your machine learning deployment. If you want to secure real-time, scalable GPU and AI-ready hardware that matches your project’s changing demands, look no further. Build on your operational insights and minimize costly downtime with a marketplace designed for enterprise-level deployments.
Take the uncertainty out of procurement and focus on performance optimization instead. Visit Nodestream by Blockware Solutions to access verified, bulk-orderable HPC equipment and GPU servers for any ML workflow. Our platform delivers transparent transactions, expert logistics, and enterprise service support so you never have to worry about scaling delays or infrastructure gaps. Need a tailored solution for a large-scale rollout? Connect now at https://nodestream.blockwaresolutions.com and turn deployment challenges into a competitive advantage today.
Effective ML project deployment involves assessing your current infrastructure, configuring the deployment environment, integrating and calibrating ML models, executing the deployment process, validating and testing outcomes, and continuously monitoring performance and optimizing resources.
Assessing current infrastructure is crucial to identify potential bottlenecks, compatibility issues, and resource gaps. A comprehensive evaluation ensures your technology can support the demands of ML workflows and helps in planning for necessary upgrades.
To ensure consistency, create a standardized environment using containerization technologies like Docker or Kubernetes. Additionally, apply infrastructure-as-code principles with tools like Ansible or Terraform to script and version your deployment infrastructure.
Implement advanced monitoring tools to track model performance, resource consumption, prediction latency, and potential anomalies. Establish automated alert systems to quickly identify deviations and streamline responses to maintain operational efficiency.
AI computing is quietly redrawing the boundaries of crypto, finance, and high-performance computing. Brace yourself. By…
Artificial intelligence is turbocharging the world of finance as never before, shaking up how both…
Digital transformation is about to completely reshape how we use crypto and artificial intelligence in…


